Baseline(HandoverSim2real) - success rate(%): 75.23
Method
GenH2R-Sim
Previous simulator only captures real-world human grasping objects in a limited manner (only 1000 scenes with 20 distinct objects). We introduce a new environment, GenH2R-Sim, to overcome these deficiencies and facilitate generalizable handovers.
Grasping poses: we use DexGraspNet to generate a substantial dataset of human hand grasp poses. We utilize this method to generate approximately 1,000,000 grasp poses for 3,266 different objects sourced from ShapeNet.
Hand-object moving trajectories: We use multiple Bézier curves to model different stages of the motion, and link the ends of these curves to create a seamless track.
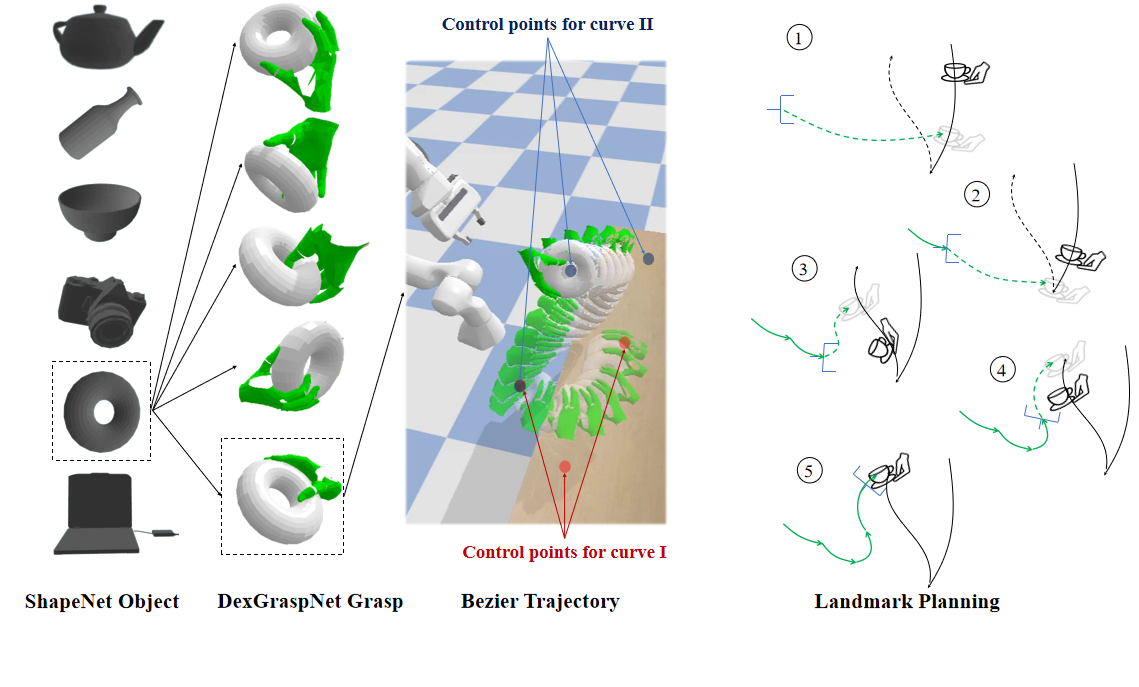
Generating Demonstrations for Distillation
To scale up robot demonstrations, we propose to automatically generate demonstrations with grasp and motion planning using privileged human motion and object state information.
We address a key question in learning visuomotor policy: how to efficiently generate robot demostrations that incorporate paired vision-action data from successful task experiences.
We identify the vision-action correlation between visual observations and planned actions as the crucial factor influencing distillability. We present a distillation-friendly demonstration generation method that sparsely samples handover animations for landmark states and periodically replans grasp and motion based on privileged future landmarks.
Forecast-Aided 4D Imitation Learning
To distill the above demonstrations into a visuomotor policy, we utilize point cloud input for its richer geometric information and smaller sim-vs-real gap compared to images.
We propose a 4D imitation learning method that factors the sequential point cloud observations into geometry and motion parts, facilitating policy learning by better revealing the current scene state.
Furthermore, the imitation objective is augmented by a forecasting objective which predicts the future motion of the handover object. vision-action correlation.

Experiments
Simulation Experiments
In the s0(sequential) benchmark:
Our model can find better grasps, especially for challenging objects.
Ours - success rate(%): 86.57
In the s0(simultaneous) benchmark:
Our model adjusts both the distance from the object and the pose to avoid frequent pose adjustments when the gripper is close to the object.
Baseline(HandoverSim2real) - success rate(%): 68.75
Ours - success rate(%): 85.65
In the t0 benchmark:
Our model predicts the future pose of the object to enable more reasonable approaching trajectories.
Baseline(HandoverSim2real) - success rate(%): 29.17
Ours - success rate(%): 41.43
In the t1 benchmark:
Our model can generalize to unseen real-world objects with diverse geometries.
Baseline(HandoverSim2real) - success rate(%): 52.4
Ours - success rate(%): 68.33
Real-world Experiments
For more complex trajectories including rotations, our model demonstrates robustness compared to baseline methods.
Baseline (HandoverSim2real)
Ours
For novel objects with complex trajectories, our model exhibits greater generalizability.
Baseline (HandoverSim2real)
Ours
BibTeX
If you have any questions, please contact:
Zifan Wang (wzf22@mails.tsinghua.edu.cn)
Junyu Chen (junyu-ch21@mails.tsinghua.edu.cn)
BibTeX
@article{wang2024genh2r,
title={GenH2R: Learning Generalizable Human-to-Robot Handover via Scalable Simulation, Demonstration, and Imitation},
author={Wang, Zifan and Chen, Junyu and Chen, Ziqing and Xie, Pengwei and Chen, Rui and Yi, Li},
journal={arXiv preprint arXiv:2401.00929},
year={2024}
}